
I am Yihao Zhang (张益豪), a senior student at the School of Mathematical Sciences, Peking University (GPA 3.55/4). I served as a visiting research assistant at Singapore Management University, from October 2023 to May 2024. Simultaneously, I am pursuing a Ph.D. in Applied Mathematics at the School of Mathematical Sciences, Peking University, thanks to the Applied Mathematics Elite Program. I am currently conducting research under the guidance of Professor Meng Sun and am a part of his research group. My supervisor at Singapore Management University is Jun Sun.
My research interests include formal methods, model checking, AI model explanation/verification/safety issues, AI-aided automatic verification, and transparency of large language models. I have published 7 papers at different international conferences with total google scholar 
Currently, I am following representation-related works on LLMs. If you are interested in this track of papers, I would appreciate it if you contacted me. I am also interested in formal methods for Quantum Computing and Software Testing Methods Towards Modern AI Models. My email: jekyllzhang@gmail.com.
If you wish to access my personal homepages prior to 2024, please click here.
🔥 News
- 2024.06: 🎉 I am graduating from Peking University and starting my Ph.D. My undergraduate thesis, Automata Extraction from Transformers, is posted on arxiv.
- 2024.05: 🎉 Our paper, On the Duality Between Sharpness-Aware Minimization and Adversarial Training, is accepted by ICML 2024.
- 2024.04: 🎉 I finished my paper, Towards General Conceptual Model Editing via Adversarial Representation Engineering, which is posted on arxiv. Our repository has got 5 stars🌟 on GitHub!
- 2024.03: 🔗 2 Papers (as first author and second-to-last author, respectively) accepted by ICLR 2024 R2-FM Workshop.
- 2023.12: 💸 My application for the Beijing Natural Science Foundation Undergraduate “Initiating Research” Program has been approved.
- 2023.10: ✈️ I am now going to Singapore Management University for a six-month exchange.
- 2023.09: 🎉 Our paper, MedTiny: Enhanced Mediator Modeling Language for Scalable Parallel Algorithms, is accepted by QRS-C 2023.
- 2023.05: 🎉 Our paper, Sharpness-Aware Minimization Alone can Improve Adversarial Robustness, is accepted by 2nd AdvML-Frontiers@ICML 2023.
- 2023.04: 🎉🎉 I have been accepted into the Applied Mathematics Elite Program by the School of Mathematical Sciences at Peking University (only 1 per year), which means that I am expected to spend five years here as a doctoral student.
📝 Publications
(*: Equal Contribution; ${}^\dagger$: Corresponding Author)
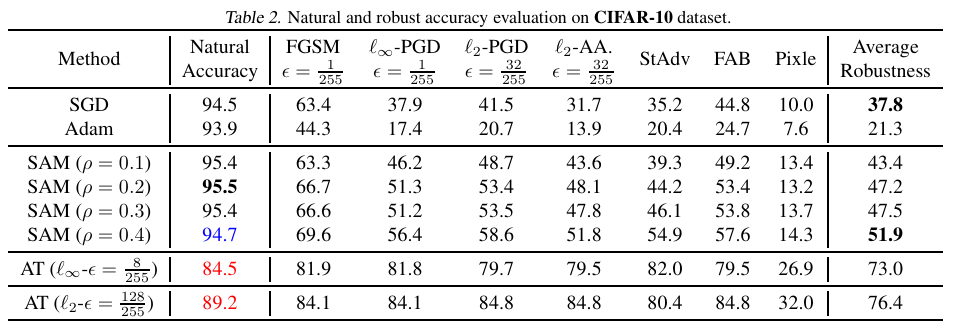
On the Duality Between Sharpness-Aware Minimization and Adversarial Training (ICML 2024)
Yihao Zhang*, Hangzhou He*, Jingyu Zhu*, Huanran Chen, Yifei Wang, Zeming Wei${}^\dagger$
Adversarial Training (AT), which adversarially perturb the input samples during training, has been acknowledged as one of the most effective defenses against adversarial attacks, yet suffers from a fundamental tradeoff that inevitably decreases clean accuracy. Instead of perturbing the samples, Sharpness-Aware Minimization (SAM) perturbs the model weights during training to find a more flat loss landscape and improve generalization. However, as SAM is designed for better clean accuracy, its effectiveness in enhancing adversarial robustness remains unexplored. In this work, considering the duality between SAM and AT, we investigate the adversarial robustness derived from SAM. Intriguingly, we find that using SAM alone can improve adversarial robustness. To understand this unexpected property of SAM, we first provide empirical and theoretical insights into how SAM can implicitly learn more robust features, and conduct comprehensive experiments to show that SAM can improve adversarial robustness notably without sacrificing any clean accuracy, shedding light on the potential of SAM to be a substitute for AT when accuracy comes at a higher priority. Code is available at this https URL.
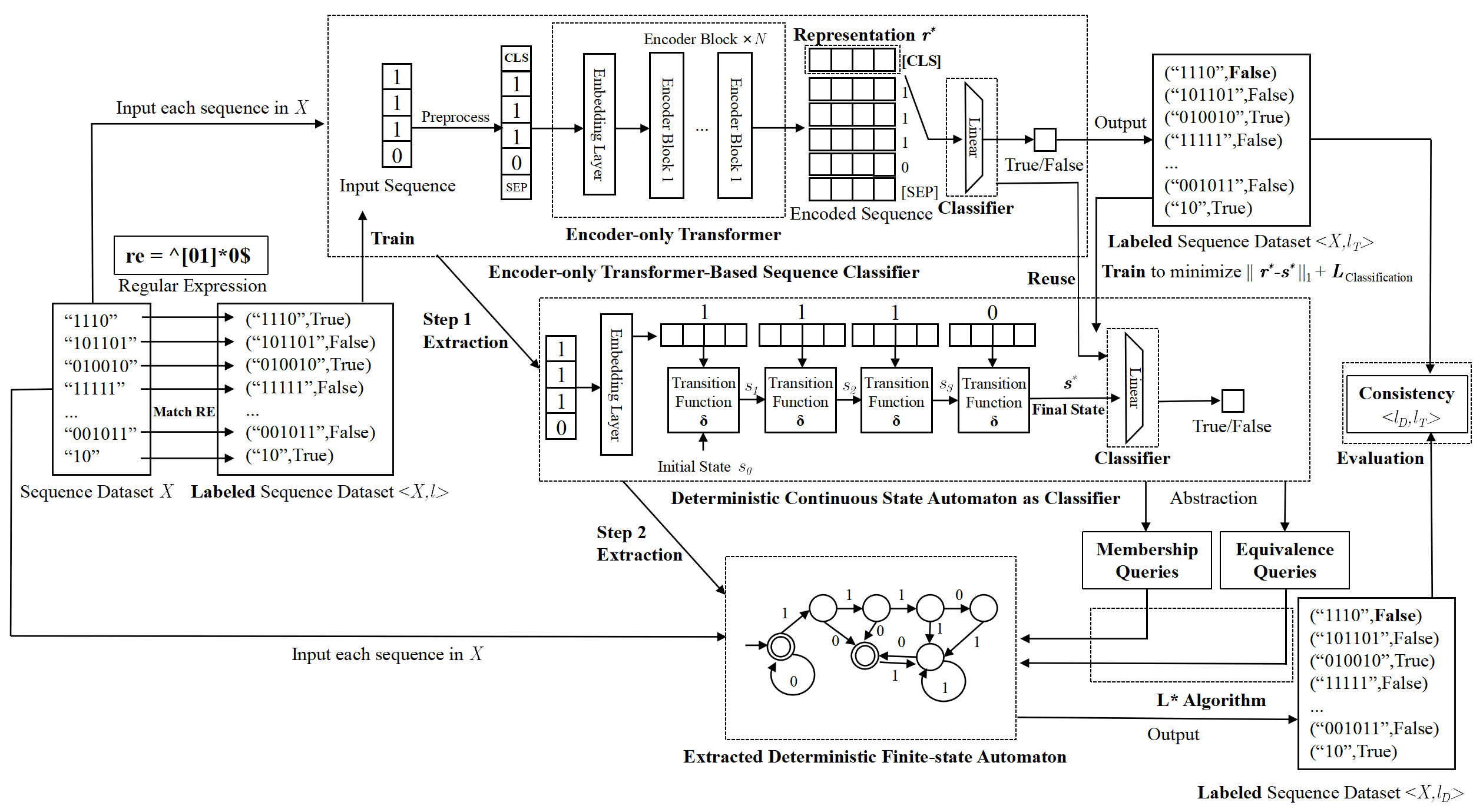
Automata Extraction from Transformers
Yihao Zhang, Zeming Wei, Meng Sun${}^\dagger$
In modern machine (ML) learning systems, Transformer-based architectures have achieved milestone success across a broad spectrum of tasks, yet understanding their operational mechanisms remains an open problem. To improve the transparency of ML systems, automata extraction methods, which interpret stateful ML models as automata typically through formal languages, have proven effective for explaining the mechanism of recurrent neural networks (RNNs). However, few works have been applied to this paradigm to Transformer models. In particular, understanding their processing of formal languages and identifying their limitations in this area remains unexplored. In this paper, we propose an automata extraction algorithm specifically designed for Transformer models. Treating the Transformer model as a black-box system, we track the model through the transformation process of their internal latent representations during their operations, and then use classical pedagogical approaches like L* algorithm to interpret them as deterministic finite-state automata (DFA). Overall, our study reveals how the Transformer model comprehends the structure of formal languages, which not only enhances the interpretability of the Transformer-based ML systems but also marks a crucial step toward a deeper understanding of how ML systems process formal languages. Code and data are available at this https URL.
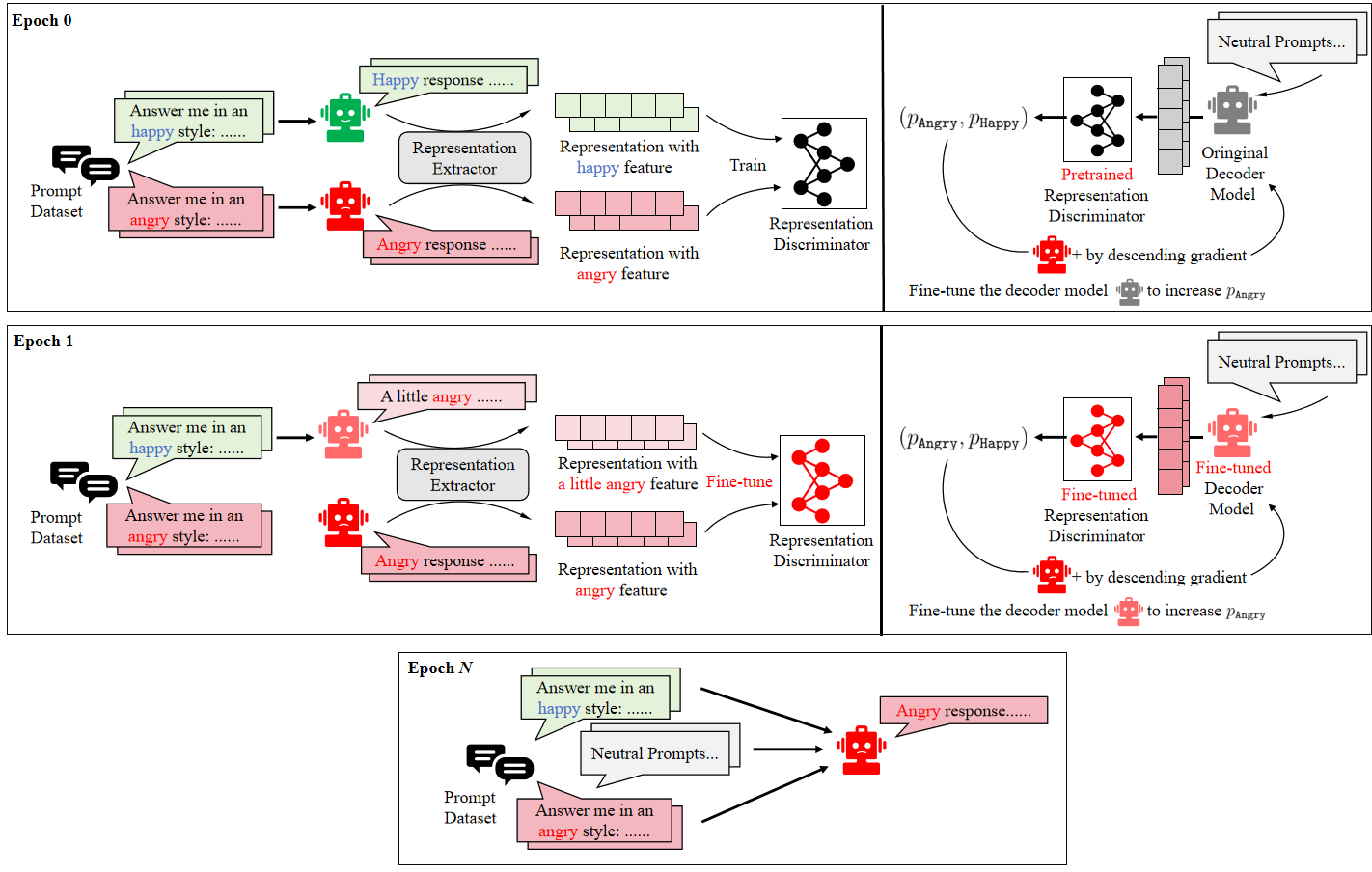
Towards General Conceptual Model Editing via Adversarial Representation Engineering (Preprint)
Yihao Zhang, Zeming Wei, Jun Sun${}^\dagger$, Meng Sun${}^\dagger$
Since the development of Large Language Models (LLMs) has achieved remarkable success, understanding and controlling their internal complex mechanisms has become an urgent problem. Recent research has attempted to interpret their behaviors through the lens of inner representation. However, developing practical and efficient methods for applying these representations for general and flexible model editing remains challenging. In this work, we explore how to use representation engineering methods to guide the editing of LLMs by deploying a representation sensor as an oracle. We first identify the importance of a robust and reliable sensor during editing, then propose an Adversarial Representation Engineering (ARE) framework to provide a unified and interpretable approach for conceptual model editing without compromising baseline performance. Experiments on multiple model editing paradigms demonstrate the effectiveness of ARE in various settings. Code and data are available at this https URL.
Weighted automata extraction and explanation of recurrent neural networks for natural language tasks (JLAMP, Vol 136)
Zeming Wei, Xiyue Zhang, Yihao Zhang, Meng Sun${}^\dagger$
Recurrent Neural Networks (RNNs) have achieved tremendous success in processing sequential data, yet understanding and analyzing their behaviours remains a significant challenge. To this end, many efforts have been made to extract finite automata from RNNs, which are more amenable for analysis and explanation. However, existing approaches like exact learning and compositional approaches for model extraction have limitations in either scalability or precision. In this paper, we propose a novel framework of Weighted Finite Automata (WFA) extraction and explanation to tackle the limitations for natural language tasks. First, to address the transition sparsity and context loss problems we identified in WFA extraction for natural language tasks, we propose an empirical method to complement missing rules in the transition diagram, and adjust transition matrices to enhance the context-awareness of the WFA. We also propose two data augmentation tactics to track more dynamic behaviours of RNN, which further allows us to improve the extraction precision. Based on the extracted model, we propose an explanation method for RNNs including a word embedding method – Transition Matrix Embeddings (TME) and TME-based task oriented explanation for the target RNN. Our evaluation demonstrates the advantage of our method in extraction precision than existing approaches, and the effectiveness of TME-based explanation method in applications to pretraining and adversarial example generation.
MedTiny: Enhanced Mediator Modeling Language for Scalable Parallel Algorithms (QRS 2023)
Xiangyu Li, Yihao Zhang, Xiaokun Luan, Xiaoyong Xue, Meng Sun${}^\dagger$
This paper introduces MedTiny, a streamlined component-based modeling language, evolved from Mediator. Existing modeling languages struggle to provide convenience in expressing recurrent component configurations, which are common in modern large-scale parallel computation modelsin distributed environments. Furthermore, Mediator frequently conducts repetitive flag manipulations to synchronize between distributed entities. To address these issues, we propose syntactic enhancements, including component array with static for each iterator and automatic synchronization flag manipulation.These enhancements significantly reduce code size and effectively address the aforementioned problems. After simplification, we successfully incorporate language feature enhancements into MedTiny without compromising its formality. Subsequently, we develop a prototype code generator that targets multi-threaded Python for code execution and PRISM model checker for verification. To demonstrate MedTiny’s efficiency, we include a case study on a character counting MapReduce algorithm.
[pdf]
Sharpness-aware minimization alone can improve adversarial robustness (ICML 2023 AdvML-Frontiers Workshop)
Zeming Wei*${}^\dagger$, Jingyu Zhu*, Yihao Zhang*
Sharpness-Aware Minimization (SAM) is an effective method for improving generalization ability by regularizing loss sharpness. In this paper, we explore SAM in the context of adversarial robustness. We find that using only SAM can achieve superior adversarial robustness without sacrificing clean accuracy compared to standard training, which is an unexpected benefit. We also discuss the relation between SAM and adversarial training (AT), a popular method for improving the adversarial robustness of DNNs. In particular, we show that SAM and AT differ in terms of perturbation strength, leading to different accuracy and robustness trade-offs. We provide theoretical evidence for these claims in a simplified model. Finally, while AT suffers from decreased clean accuracy and computational overhead, we suggest that SAM can be regarded as a lightweight substitute for AT under certain requirements.
Using Z3 for Formal Modeling and Verification of FNN Global Robustness (SEKE 2023)
Yihao Zhang, Zeming Wei, Xiyue Zhang, Meng Sun${}^\dagger$
While Feedforward Neural Networks (FNNs) have achieved remarkable success in various tasks, they are vulnerable to adversarial examples. Several techniques have been developed to verify the adversarial robustness of FNNs, but most of them focus on robustness verification against the local perturbation neighborhood of a single data point. There is still a large research gap in global robustness analysis. The global-robustness verifiable framework DeepGlobal has been proposed to identify \textit{all} possible Adversarial Dangerous Regions (ADRs) of FNNs, not limited to data samples in a test set. In this paper, we propose a complete specification and implementation of DeepGlobal utilizing the SMT solver Z3 for more explicit definition, and propose several improvements to DeepGlobal for more efficient verification. To evaluate the effectiveness of our implementation and improvements, we conduct extensive experiments on a set of benchmark datasets. Visualization of our experiment results shows the validity and effectiveness of the approach.
🎖 Honors and Awards
- Selected for the Elite Program (Graduate) in the School of Mathematical Sciences, Peking University.
- University Scholarship, Peking University, 2023
- Second prize, Chinese Mathematics Competitions for Undergraduates (Beijing Division), 2023
📖 Educations
- 2023.10 - 2024.05, Research Assistant, School of Computing and Information Systems, Singapore Management University.
- 2020.09 - 2024.06 (expected), Undergraduate Student, School of Mathematical Sciences, Peking University.
💬 Talks
- 2024.04, Presented our work on Adversarial Representation Engineering in an internal talk in Huawei.
- 2023.06, Presented my paper “Using Z3 for Formal Modeling and Verification of FNN Global Robustness” on SEKE 2023.
💻 Projects
- 2023-2025, Study on the interpretability of large language model architecture and algorithm, Program Director.
- 2022-2025, Trustworthy guarantee of deep learning system, Member.
🔗 Links
- 👨🏫 Advisors: Meng Sun (PKU), Jun Sun (SMU).
- 🧑🎓 Co-authors: Zeming Wei, Xiyue Zhang, Huanran Chen
📚 Academic Links
- Z3 Guide
- Z3 Tutorial
- Coq
- Software Foundations
- SPIN
- UPPAAL
- TLA+
- NuSMV
- CMinor Verifier
- CSAPP Lecture Video
- CAV
- POPL
- Open class on Constraint Solving, Bilibili
- Model Checking and Program Verification Courses & Tutorials: PKU Software Foundations, PKU Software Analysis, USTC Formal Methods, TJU Model Checking, Stanford CS357, Column of Program Verification on Zhihu